Scheduling in iota2
The control of task chaining in iota2 is very important. This is what we usually call task scheduling. A “task” is the generic term for something to be done. Fine control of these tasks provides maximum information to the user on the sequence of tasks that will be sent, which tasks will be launched in parallel, which ones will be launched sequentially, which tasks must be completed before launching others etc. In addition, in case of problems, the user will be able to find out which tasks did not finish correctly and why: special attention is given to logging.
This is why we have chosen to use dask to schedule our tasks, and more specifically dask.delayed and dask.jobqueue to respectively build the dependencies between tasks and then submit them for execution.
About dask
A lot of documentation is available on dask’s website : https://docs.dask.org/en/latest/
iota2, the context of a processing chain
Iota2 is a modular processing chain, which is capable of handling large amounts of data implementing algorithms that can be sequential and/or massively parallel. From this, we can deduce 3 major constraints which have oriented the chosen solutions for the scheduling:
modularity
This means that depending on the user’s choice, an algorithm can be activated or not and be set up differently. As a result, the sequences of tasks to be launched can be very different from one iota2 execution to another.
management of computing resources
Being able to assign a quota of resources per task is needed in order to have an optimal scheduling when iota2 is launched on infrastructures (HPC clusters, cloud) where the allocation of computing resources conditions the launch of a task and can be billable.
Step selection
iota2 must be able to provide its users with a simple interface to resume processing in the event of problems or to select the processing to be performed from a list of available steps to be processed.
This documentation proposes to guide the reader on the solution chosen in iota2 for task scheduling with dask through a simple example, to meet each of the constraints expressed above. Then, the final solutions implemented in iota will be shown. The proposed example is not representative of the sequence of steps actually performed in iota2.
Modularity
dask.delayed : how to use it ?
dask.delayed objects are used in iota2 to define the dependencies between steps and tasks.
Warning
in iota2 we use the term “step” to refer to executions that have a common purpose. For example learning, classifying and validating classifications are 3 distinct steps: at each launch of iota2, a summary of the steps to be launched is shown to the user. In this documentation, we will also talk about tasks. From this point on, tasks will designate a subset of a step. For example, the learning step will consist of 2 tasks: “learning model 1” and “learning model 2”.
First, let’s construct a simple tasks dependency thanks to two simple functions. The purpose is to launch once function_A. Once completed, launch function_B once.
def function_A(arg_a: int) -> int
"""
"""
print(arg_a)
return arg_a + 1
def function_B(arg_b: int) -> int:
"""
"""
print(arg_b)
return arg_b + 1
a_return = function_A(1)
print("between two functions call")
b_return = function_B(a_return)
print(b_return)
then without surprise, we get the trace
1
between two functions call
2
3
However, by using dask.delayed :
a_return = dask.delayed(function_A)(1)
print("between two functions call")
b_return = dask.delayed(function_B)(a_return)
print(b_return)
between two functions call
Delayed('function_B-66d71002-295c-4711-8c86-4a3184ee6163')
We only get a delayed object, no function has been executed. In order to trigger some processing, we must use the compute() method from the delayed object b_return. Then we get :
a_return = dask.delayed(function_A)(1)
print("between two function call")
b_return = dask.delayed(function_B)(a_return)
print(b_return)
res = b_return.compute()
print(res)
between two function call
Delayed('function_B-66d71002-295c-4711-8c86-4a3184ee6163')
1
2
3
This is the common usage of dask.delayed objects : use returned object to generate a complete graph and submit it using compute() or equivalent. However in iota2, functions do not fit to this kind of use: functions are more data oriented and most functions return the None object. The following code snippet illustrates this:
def learn_model(vector_file: str, output_model: str) -> None:
""" learn model according to features stored in a vector file
"""
print(f"I'm learning {output_model} thanks to {vector_file}")
def classify_tile(model_file: str, output_classif: str) -> None:
""" perform classification thanks to a model
"""
print(f"classification of {output_classif} thanks to {model_file}")
Dask assumes that every functions can communicate through their API (function’s inputs and outputs) and then, thanks to these communications, deduce an execution graph. In iota2 the dependencies can be strong between certain stages (learning then classification) whereas it is not possible to express a dependency between these tasks understandable by dask. To control the dependencies between these tasks, a solution could have been to impose a type of return to these functions and their input, but this then constrains the use of these functions to an internal use in iota2, which is not the purpose of these functions.
That’s why, in order to be as generic as possible, we have decided not to impose any particular type of return to these functions launched by dask. The chosen solution is to use a function that wraps the function to be executed, this function will be called tasks_launcher().
rewrite the previous test using tasks_launcher()
def task_launcher(*args: List[dask.delayed], **kwargs) -> None:
# deep copy to avoid side effect.
kwargs = kwargs.copy()
task_kwargs = kwargs.get("task_kwargs", None)
if task_kwargs:
# get the function to execute
func = task_kwargs["f"]
# remove it from the input dictionnary
task_kwargs.pop('f', None)
# use the input dictionary as parameters of the stored function
# the next line launch the task
func(**task_kwargs)
database_file = "my_database.sqlite"
model_file = "model_1.txt"
from_learn_model = dask.delayed(task_launcher)(task_kwargs={
"f": learn_model,
"vector_file": database_file,
"output_model": model_file
})
classification_1 = "Classif_1.tif"
res = dask.delayed(task_launcher)(from_learn_model,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
})
res.compute()
This time the execution and arguments are respected. To completely understand the workflow two points must be understood:
the functioning of dask.delayed(function_to_delayed)(parameters_of_function_to_delayed)
if one of the parameters of the delayed function is a dask.delayed, then the parameter will be triggered/executed before the function is called, for instance:
def some_function(arg1, arg2: int): ... A = dask.delayed(...)(...) delayed_return = dask.delayed(some_function)(A, 2) delayed_return_value = delayed_return.compute()In this example, A is a dependency of some_function. Therefore, A will be executed before the call to some_function.
It is this behaviour that allows the dependencies to be expressed in iota2.
This behaviour enables us to submit parallel tasks.
Note
The number of tasks that can be executed in parallel should not be confused with the actual number of tasks executed at the same time. Indeed, the number of tasks actually launched in parallel depends mainly on the resources available at the time when iota2 must launch a task.
Submitting parallel tasks
Now that the system of dependencies between functions is set up, let’s see how to integrate multiple dependencies with the following example: “generate 2 models before launching the classification of a tile, both models can be computed in parallel”. We can schematize this exercise by the following diagram:
model_1 model_2
\ /
\ /
classification
model_1_delayed = dask.delayed(task_launcher)(task_kwargs={
"f": learn_model,
"vector_file": database_file,
"output_model": model_file_1
})
model_2_delayed = dask.delayed(task_launcher)(task_kwargs={
"f": learn_model,
"vector_file": database_file,
"output_model": model_file_2
})
classification_1 = "Classif_1.tif"
res = dask.delayed(task_launcher)(model_1_delayed,
model_2_delayed,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
})
# there is no execution until the next line
res.compute()
In the exemple above, model_1_delayed and model_2_delayed become dependencies of the execution of the function task_launcher which will launch the classification function. Consequently, the function learn_model will be executed twice before the classify_tile call.
Also, we can re-write dependencies like the following :
dependencies = [model_1_delayed, model_2_delayed]
res = dask.delayed(task_launcher)(*dependencies,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
})
# there is no execution until the next line
res.compute()
Two key points can be concluded from this example:
we can store dependencies (delayed objects) in a usual Python list.
the first parameter of task_launcher(),
*args, represents the variable number of dependencies. Thanks to it, it is pretty easy to express dependencies between functions as long as the parameters of the functions to launch are known beforehand. Indeed, every task_kwargs parameters must contain the exhaustive list of parameters of the function to launch.
Submitting tasks
We have seen that in order to trigger processing, we must use the compute() function of the dask.delayed objects. This method allows us to execute locally the desired function. However, dask also offers the possibility to trigger the execution on different computing architectures. This is what is proposed by the dask_jobqueue module. In iota2, we will give special attention to the LocalCluster and PBSCluster objects which allow respectively to create a cluster on a local machine or to use a physical HPC cluster managed with PBS.
We had :
...
res = dask.delayed(task_launcher)(*dependencies,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
})
# there is no execution until the next line
res.compute()
now we get
if __name__ == '__main__':
from dask.distributed import Client
from dask.distributed import LocalCluster
from dask_jobqueue import PBSCluster
...
res = dask.delayed(task_launcher)(*dependencies,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
})
cluster = PBSCluster(n_workers=1, cores=1, memory='5GB')
client = Client(cluster)
# there is no execution until next line
sub_results = client.submit(res.compute)
# wait until tasks are complete
sub_results.result()
Note
In order to reproduce the examples and if you don’t have an access to a HPC cluster scheduled by PBS, you can replace the line :
cluster = PBSCluster(n_workers=1, cores=1, memory='5GB')
by
cluster = LocalCluster(n_workers=1, threads_per_worker=1)
Here, a cluster object is created with one worker, one core and 5 Gb of RAM. Then tasks are sent to the PBS scheduler using the submit function.
You may notice that resources can now be chosen. Now we will have a look on how we can assign resources to different tasks in iota2.
Set ressources by task
Currently, dask does not offer a solution for attaching resources by task, so we have to find a way to do this. For this, we will rely on the task_launcher() function which is the place where each task is sent. In fact, we are going to add a new parameter to this function, a python dictionary, which will characterize the resources needed to execute a task. These resources will be used to create inside the task_launcher() function a cluster object with the correct resource allocation. It is on this cluster, instantiated in task_launcher(), that the task will be executed.
Here is its definition:
def task_launcher(*args: List[dask.delayed],
resources={"cpu": 1,
"ram": "5Gb"},
**kwargs) -> None:
kwargs = kwargs.copy()
task_kwargs = kwargs.get("task_kwargs", None)
if task_kwargs:
# get the function to execute
func = task_kwargs["f"]
# remove it from the input dictionnary
task_kwargs.pop('f', None)
# next line launch the function locally
# func(**task_kwargs)
# next lines deploy the function to the cluster with the necessary resources.
cluster = PBSCluster(n_workers=1,
cores=resources["cpu"],
memory=resources["ram"])
client = Client(cluster)
client.wait_for_workers(1)
sub_results = client.submit(func, **task_kwargs)
sub_results.result()
# shutdown the cluster/client dedicated to one task
cluster.close()
client.close()
Every task has to create its own cluster object with the appropriate resource allocation. Once the cluster is ready, the tasks can be executed on it. So now, if learning tasks are monothreaded and the classification task is multithreaded, our main code may looks like:
if __name__ == '__main__':
database_file = "my_database.sqlite"
model_file_1 = "model_1.txt"
model_file_2 = "model_2.txt"
model_1_delayed = dask.delayed(task_launcher)(task_kwargs={
"f": learn_model,
"vector_file": database_file,
"output_model": model_file_1
},
resources={
"cpu": 1,
"ram": "5Gb"
})
model_2_delayed = dask.delayed(task_launcher)(task_kwargs={
"f": learn_model,
"vector_file": database_file,
"output_model": model_file_2
},
resources={
"cpu": 1,
"ram": "5Gb"
})
classification_1 = "Classif_1.tif"
dependencies = [model_1_delayed, model_2_delayed]
res = dask.delayed(task_launcher)(*dependencies,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
},
resources={
"cpu": 2,
"ram": "10Gb"
})
cluster = LocalCluster(n_workers=1)
client = Client(cluster)
client.wait_for_workers(1)
# there is no execution until next line
sub_results = client.submit(res.compute)
# wait until tasks are terminated
sub_results.result()
In the example above, we have the learning tasks that will start with a resource reservation of 1 CPU and 5GB of RAM while the classification step will be sent with a resource reservation twice as large.
At this point, we can say that two thirds of the scheduling solution is already in place, because scheduling allows dependencies between tasks and the assignment of resources by task is possible. The last phase that remains to be dealt with is offering the possibility for users to select a step interval to be executed. This is the subject of the following section.
Enable and disable steps
In a processing chain composed of several steps it can sometimes be interesting for users to select a step interval to rerun. Several use cases can lead the user to make this choice: replaying a processing chain in case of errors, some steps are not necessary because already done outside iota2 (learning a model, generating a database, …) or the user wants to rerun a step but with different parameters. iota2 must be able to offer this kind of service which is very appreciated by users, but also by step developers.
Problem illustration, thanks to the previous example
In the previous example, the task sequence graph is rigid, in the sense that if a step (the group of learning tasks and/or classification) is removed, no execution will be possible: the dependency tree is broken. The goal here is to find a generic way to express a step sequence that will work regardless of the steps that are removed from the execution graph. A first trivial solution will be exposed, its limitations will show that it is necessary to move towards a more complex and generic solution which is the one implemented in iota2.
remove the last task
Based on the solution proposed previously, it is relatively easy to manage the case where only the classification is desired. Assuming the second python argument is the first step index to execute and the third argument the last one.
if __name__ == '__main__':
import sys
first_step = int(sys.argv[1])
last_step = int(sys.argv[2])
...
if first_step == 1 and last_step == 2:
res = dask.delayed(task_launcher)(*dependencies,
task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif":
classification_1
},
resources={
"cpu": 2,
"ram": "10Gb"
})
elif first_step == 2 and last_step == 2:
# if only the classification is asked, then classifications tasks get no dependencies
res = dask.delayed(task_launcher)(task_kwargs={
"f": classify_tile,
"model_file": database_file,
"output_classif": classification_1
},
resources={
"cpu": 2,
"ram": "10Gb"
})
...
sub_results = client.submit(res.compute)
sub_results.results()
This solution works when only the last step is required. If only the classification step is required (first_step == last_step == 2), then the classification taks get no dependencies. However, the solution will not work when only the learning tasks are requested. Indeed, the line :
sub_results = client.submit(res.compute)
will not be able to launch the learning tasks because the variable res (defining the tasks to be launched) and dependencies (containing the learning tasks) have different types: one is a dask.delayed and the other is a list of dask.delayed. A generic way to send tasks to the cluster must therefore be found. Below is the one proposed in iota2: a container of the last steps to be sent, step_tasks.
remove the first task
if __name__ == '__main__':
import sys
first_step = int(sys.argv[1])
last_step = int(sys.argv[2])
...
step_tasks = []
if first_step == 1:
model_1_delayed = dask.delayed(task_launcher)(...)
model_2_delayed = dask.delayed(task_launcher)(...)
step_tasks = [model_1_delayed, model_2_delayed]
...
if first_step == 1 and last_step == 2:
dependencies = [model_1_delayed, model_2_delayed]
classif_delayed = dask.delayed(task_launcher)(*dependencies, ...)
step_tasks.append(classif_delayed)
elif first_step == 2 and last_step == 2:
classif_delayed = dask.delayed(task_launcher)(...)
step_tasks.append(classif_delayed)
# there is no execution until the next line
final_dask_graph = dask.delayed(task_launcher)(*step_tasks)
sub_results = client.submit(final_dask_graph.compute)
# wait until tasks are terminated
sub_results.result()
The step_tasks container is redefined for each step and contains all the tasks to be launched for a step. This step container, through the use of task_launcher(), enables gathering all the tasks defined in a step of iota2.
All scheduling constraints have been exposed and solved, the following script summarizes all these solutions by introducing an additional complexity which is present in iota2, all steps are represented by classes. Thus, this script allows to be the minimal representation of what scheduling is in iota2.
Scheduling solution in iota2
It is easy to notice that steps have common functionnalities: creating tasks, associating dependencies to them and launching tasks. All these steps common features have been gathered in the base class: i2_step().
The next section shows the slightly simplified, but functional, definition of this class and parallels between the definition of this class and the previous examples are highlighted.
It is therefore important that the examples 1, 2 and 3 are well understood.
Base class dedicated to steps
class i2_step():
"""base class for every iota2 steps"""
class i2_task():
"""class dedicated to reprensent a task in iota2"""
def __init__(self, task_parameter: Dict, task_resources: Dict):
self.task_parameter = task_parameter
self.task_resources = task_resources
step_container = []
tasks_graph = {}
# parameters known before the iota2's launch
database_file = "my_database.sqlite"
models_to_learn = ["model_1.txt", "model_2.txt"]
classifications_to_perform = ["Classif_1.tif"]
def __init__(self):
self.step_container.append(self)
self.step_tasks = []
@classmethod
def get_final_execution_graph(cls):
return dask.delayed(
cls.task_launcher)(*cls.step_container[-1].step_tasks)
def task_launcher(*args: List[dask.delayed], resources={"cpu": 1, "ram": "5Gb"}, **kwargs) -> None:
"""method to launch task"""
kwargs = kwargs.copy()
task_kwargs = kwargs.get("task_kwargs", None)
if task_kwargs:
func = task_kwargs["f"]
task_kwargs.pop('f', None)
task_cluster = PBSCluster(n_workers=1,
cores=resources["cpu"],
memory=resources["ram"])
task_client = Client(task_cluster)
task_client.wait_for_workers(1)
task_results = task_client.submit(func, **task_kwargs)
task_results.result()
task_cluster.close()
task_client.close()
# func(**task_kwargs)
def add_task_to_i2_processing_graph(
self,
task,
task_group: str,
task_sub_group: Optional[str] = None,
task_dep_dico: Optional[Dict[str, List[str]]] = None) -> None:
"""use to build the tasks' execution graph
"""
if task_group not in self.tasks_graph:
self.tasks_graph[task_group] = {}
# if there is no steps in the step container that mean no dependencies have
# to be set
if len(self.step_container) == 1:
new_task = dask.delayed(self.task_launcher)(
task_kwargs=task.task_parameter, resources=task.task_resources)
else:
task_dependencies = []
for task_group_name, tasks_name in task_dep_dico.items():
if task_group_name in self.tasks_graph:
for dep_task in tasks_name:
task_dependencies.append(
self.tasks_graph[task_group_name][dep_task])
new_task = dask.delayed(self.task_launcher)(
*task_dependencies,
task_kwargs=task.task_parameter,
resources=task.task_resources)
# update the dependency graph
self.tasks_graph[task_group][task_sub_group] = new_task
# save current step's tasks
self.step_tasks.append(new_task)
This class allows the possibility to define dependencies between tasks and to have different resources per task using the task_launcher() function which has exactly the same definition as in the examples above.
Also, dependencies between tasks are managed thanks to the add_task_to_i2_processing_graph().
This function relies on the class attribute “tasks_graph” which, like “dependencies” in the example 2,
allows to save the dependencies between tasks and thus build a dependency graph using dask.
However, tasks_graph and dependencies are a bit different: dependencies was a simple list of dask.delayed objects, while tasks_graph is a dictionary of dictionaries.
This change makes it possible to ‘name’ the dependencies and to be more explicit than a simple list when traveling between stages.
All dependency management between tasks will be handled by the class attribute tasks_graph and the method add_task_to_i2_processing_graph().
Each task must belong to a task_group and must define its dependencies if needed. For example, let’s take the previous example where 2 models have to be created.
So there will be 2 tasks that we will name “model_1.txt” and “model_2.txt” that we will group together under the task_group “models”.
Somewhere in the code, there will be a call to add_task_to_i2_processing_graph() like this:
add_task_to_i2_processing_graph(task, "models", "model_1.txt")
...
add_task_to_i2_processing_graph(task, "models", "model_2.txt")
where task is a class containing two dictionaries, one describing the task and the other describing the task resources. These dictionaries are the same that the ones we can find in 3 under the names task_kwargs and resources.
Warning
There are no special naming conventions for task_group and task_sub_group variables, users can name them as they wish.
No dependencies have been mentioned because the learning step will be the first step in our example processing chain. We can define our learning step as a class that inherits the functionality of the i2_step class :
class learn_model(i2_step):
"""class simulation the learn of models"""
def __init__(self):
super(learn_model, self).__init__()
for model in self.models_to_learn:
model_task = self.i2_task(task_parameter={
"f": self.learn_model,
"vector_file": self.database_file,
"output_model": model
},
task_resources={
"cpu": 1,
"ram": "5Gb"
})
self.add_task_to_i2_processing_graph(model_task,
task_group="models",
task_sub_group=model)
def learn_model(self, vector_file: str, output_model: str) -> None:
""" learn model according to features stored in a vector file
"""
print(f"I'm learning {output_model} thanks to {vector_file}")
Likewise, we can define the classification step
class classifications(i2_step):
"""class to simulate classifications"""
def __init__(self):
super(classifications, self).__init__()
classification_task = self.i2_task(task_parameter={
"f":
self.classify_tile,
"model_file":
self.models_to_learn[0],
"output_classif":
self.classifications_to_perform[0]
},
task_resources={
"cpu": 2,
"ram": "10Gb"
})
self.add_task_to_i2_processing_graph(
classification_task,
task_group="classifications",
task_sub_group=self.classifications_to_perform[0],
task_dep_dico={"models": self.models_to_learn})
def classify_tile(self, model_file: str, output_classif: str) -> None:
"""
"""
print(f"classification of {output_classif} thanks to {model_file}")
This time, dependencies have been set when creating the classification task: the classification task needs both learning tasks to be completed in order to be run.
task_dep_dico={"models": self.models_to_learn}
which means: “I need that every task named as in the list of tasks names self.models_to_learn of the group of tasks ‘models’ has been finished to be launched”.
Furthermore, it is possible to create tasks which depend of many groups of tasks. Let’s create a new class : confusion which depends on the classification and one learning task.
class confusion(i2_step):
"""class to simulate classifications"""
def __init__(self):
super(confusion, self).__init__()
confusion_task = self.i2_task(task_parameter={
"f": self.confusion,
"output_confusion_file": "confusion.csv"
},
task_resources={
"cpu": 2,
"ram": "10Gb"
})
self.add_task_to_i2_processing_graph(
confusion_task,
task_group="confusion",
task_sub_group="confusion_tile_T31TCJ",
task_dep_dico={
"classifications": [self.classifications_to_perform[0]],
"models": [self.models_to_learn[-1]]
})
def confusion(self, output_confusion_file) -> None:
"""
"""
print(f"generetating confusion : {output_confusion_file}")
This class generates only one task, which depends on the first classification task (actually, there is only one) and the last task of learning step.
Once our step classes are defined, it is time to instanciate them.
To achieve this pupose, we use the class called i2_builder() which manages the step’s instanciation
considering 2 parameters: the index of the first and the last step to be launched. This way, we satisfy the last constraint: being able to select an interval of steps to execute in a sequence of steps.
Then after the call of get_final_i2_exec_graph(), the full processing chain will be ready to be launched. Actually,
the only purpose of this method is to instanciate the required steps and by extension build the final dask graph.
Note
self.step_tasks and the varialbe step_tasks in example 3 have the same goal, save step’s tasks
class i2_builder():
"""define step sequence to be launched"""
def __init__(self, first_step: int, last_step: int):
self.first_step = first_step
self.last_step = last_step
self.steps = self.build_steps()
if self.last_step > len(self.steps):
raise ValueError(f"last step must be <= {len(self.steps)}")
def build_steps(self):
"""prepare steps sequence"""
from functools import partial
steps_constructors = []
steps_constructors.append(partial(learn_model))
steps_constructors.append(partial(classifications))
steps_constructors.append(partial(confusion))
return steps_constructors
def get_final_i2_exec_graph(self):
# instanciate steps which must me launched
steps_to_exe = [
step() for step in self.steps[self.first_step:self.last_step + 1]
]
return i2_step.get_final_execution_graph()
if __name__ == '__main__':
import sys
run_first_step = int(sys.argv[1]) - 1
run_last_step = int(sys.argv[2]) - 1
assert run_last_step >= run_first_step
i2_chain = i2_builder(run_first_step, run_last_step)
graph = i2_chain.get_final_i2_exec_graph()
graph.compute()
These orchestration classes, are functional and enable to meet the constraints previously mentioned. One last constraint has not yet been cited and is related to dask: when a graph is built, it is impossible to modify it during its call. Once launched, it is necessary to wait for the end of the execution before doing anything else. This trivial constraint can have serious consequences for some chain executions where in some particular cases the number of tasks to be launched cannot be determined before submiting computations. In the figure below, the task \(T_3\) have two dependencies : \(T_1\) and \(T_2\) and produce a number of dependencies which is only know after it’s execution. The complete graph, from \(T_4\) to \(T_N\), can’t be build.
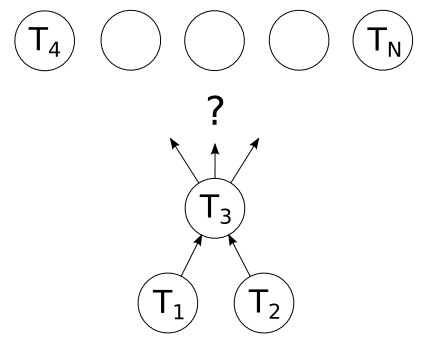
Step generating a non-deterministic number of dependencies
In iota2, we propose to bypass this constraint thanks to the creation of several independent execution graphs. The following section will complement the i2_builder and i2_step classes to satify the following scenario:
Currently, there are 3 steps in a sequence, the steps of learning, classify and then confusion. We are going to add a new step to report production. The class dedicated to the production of these tasks is named report. In this scenario, the confusion step will generate a random number of files and for each of these files, the report class will have to associate it a task. The report class must deal with the randomness of its dependencies.
The first change to be made concerns the object that will contain the steps. Previously, in the i2_builder class, we used a simple list called steps_constructors. This list simply stored the steps that will be launched later in the execution phase. In the proposed solution, we will replace this list with a class that we will create : step_container() whose definition is as follows
class step_container():
list_of_name = set()
def __init__(self,
container_name: Optional[str] = "i2_step_container",
callback=None):
self.name = container_name
if self.name in self.list_of_name:
raise ValueError(f"{self.name} already exists")
self.list_of_name.add(container_name)
self.container = []
self.callback = callback
def append(self, step):
self.container.append(step)
# next line inform the step instance, the name of it's container owner
step.func.container_name = self.name
def __setitem__(self, index, val):
self.container[index] = val
def __getitem__(self, index):
return self.container[index]
def __len__(self):
return len(self.container)
As you can observe, This class needs two parameters to be instantiated: a name and a partial function (ready to be executed). These two parameters enable the class to satisfy these two main purposes:
Inform the step of the name of the container that contains it. It is this name which, as we will see in the next code snippet, will determine the execution graph of the step.
Associate a function (the callback function) to a particular step container. This function could, for example, be triggered before the execution of a sequence of steps.
The method add_task_to_i2_processing_graph() of class i2_step must therefore be modified to be able to generate different execution graphs according to the information sent by the “step_container” (the execution graph to feed)
def add_task_to_i2_processing_graph(
self,
task,
task_group: str,
task_sub_group: Optional[str] = None,
task_dep_dico: Optional[Dict[str, List[str]]] = None) -> None:
"""use to build the tasks' execution graph
"""
if not self.container_name in self.tasks_graph:
self.tasks_graph[self.container_name] = {}
if task_group not in self.tasks_graph[self.container_name]:
self.tasks_graph[self.container_name][task_group] = {}
if not task_dep_dico:
new_task = dask.delayed(self.task_launcher)(
task_kwargs=task.task_parameter, resources=task.task_resources)
else:
task_dependencies = []
for task_group_name, tasks_name in task_dep_dico.items():
if task_group_name in self.tasks_graph[self.container_name]:
for dep_task in tasks_name:
task_dependencies.append(self.tasks_graph[
self.container_name][task_group_name][dep_task])
new_task = dask.delayed(self.task_launcher)(
*task_dependencies,
task_kwargs=task.task_parameter,
resources=task.task_resources)
self.tasks_graph[
self.container_name][task_group][task_sub_group] = new_task
self.step_tasks.append(new_task)
Warning
In the previous solution, the tasks_graph class attribute was a dependency graph, whereas now it is a dictionnary of dependency graph where each key in the dictionary is actually given by the name of the step container.
It is important to notice that we have created two containers. The first one contains the first steps already built and the second one contains only the report creation step, these two containers generate two independants dask graphs. Since the confusing step generates a random number of files at runtime, it is impossible to predict in advance the dependencies of the reporting step. This is why the report step is placed alone in a container, we will see later in another section how the callback function will enable us to help the report creation step to create as many tasks as necessary.
The second method to be modified in class i2_builder is get_final_i2_exec_graph. The goal of this method will be to prepare the dask graphs, according to the steps requested by the user for their execution.
def get_final_i2_exec_graph(self) -> List[waiting_i2_graph]:
"""
"""
i2_graphs = []
# Assuming that self.first_step and self.last_step are respectively
# the index of the first and last step requested by the user
indexes = self.get_indexes_by_container(self.first_step,
self.last_step)
for container, tuple_index in zip(self.steps_containers, indexes):
if tuple_index:
container_start_ind, container_end_ind = tuple_index
i2_graphs.append(
waiting_i2_graph(self, container, container_start_ind,
container_end_ind, container.callback))
return i2_graphs
def get_indexes_by_container(self, first_step_index,
last_step_index) -> List[Tuple[int, int]]:
""" the purpose of this function is to get for each container of steps,
indexes of steps to process according to user demand.
print([len(steps_container) for steps_container in self.build_steps()])
>>> [3, 1]
print(self.get_indexes_by_container(0, 0))
>>> [(0, 0), []]
print(self.get_indexes_by_container(0, 4))
>>> [(0, 2), (0, 0)
"""
import numpy as np
remaining_steps = len(np.arange(first_step_index, last_step_index + 1))
buffer_index = []
len_buff = 0
for cpt, container in enumerate(self.steps_containers):
buffer_index.append([])
if first_step_index != 0:
first_step_graph = first_step_index - len_buff
else:
first_step_graph = 0
len_buff = len(container)
if first_step_graph > len(container) - 1:
continue
for elem in range(first_step_graph, len(container)):
if remaining_steps == 0:
break
buffer_index[cpt].append(elem)
remaining_steps -= 1
container_indexes = []
for index_list in buffer_index:
if index_list:
container_indexes.append((index_list[0], index_list[-1]))
else:
container_indexes.append([])
return container_indexes
For each graph, we prepare its execution thanks to the use of waiting_i2_graph class. This class will allow us to build the dependency graph after calling the callback function.
class waiting_i2_graph():
"""
data class containing dask's graph ready to be build.
"""
def __init__(self,
builder,
steps_container,
starting_step,
ending_step,
callback_function=None):
self.container = steps_container
self.starting_step = starting_step
self.ending_step = ending_step
self.callback = callback_function
self.builder = builder
self.figure_graph = None
def build_graph(self):
if self.callback:
self.callback()
# call every needed steps constructor
_ = [
step()
for step in self.container[self.starting_step:self.ending_step + 1]
]
return i2_step.get_exec_graph()
The get_final_i2_exec_graph() method remains the entry point of the orchestration api. This method now returns instances of waiting_i2_graph, so the new way to send iota2 processing is as follow:
if __name__ == '__main__':
import sys
run_first_step = int(sys.argv[1]) - 1
run_last_step = int(sys.argv[2]) - 1
assert run_last_step >= run_first_step
i2_chain = i2_builder(run_first_step, run_last_step)
i2_graphs = i2_chain.get_final_i2_exec_graph()
# we sequentially call the build_graph() method for each waiting_i2_graph, building dask's graph
for i2_graph in i2_graphs:
delayed_dask_graph = i2_graph.build_graph()
# use dask's compute function as usual
delayed_dask_graph.compute()
Now that the step orchestration in iota2 enables us to launch several execution graphs one after the other we can write the step class confusion and report to respond to the scenario and see how an execution works.
class confusion(i2_step):
"""class to simulate classifications"""
def __init__(self):
super(confusion, self).__init__()
confusion_task = self.i2_task(task_parameter={
"f": self.confusion,
"output_confusion_file": "confusion.csv"
},
task_resources={
"cpu": 2,
"ram": "10Gb"
})
self.add_task_to_i2_processing_graph(
confusion_task,
task_group="confusion",
task_sub_group="confusion_tile_T31TCJ",
task_dep_dico={
"classifications": [self.classifications_to_perform[0]],
"models": [self.models_to_learn[-1]]
})
def confusion(self, output_confusion_file) -> None:
"""
"""
import random
nb_confusion = random.randint(1, 5)
print(f"number of random confusion file : {nb_confusion}")
for nb_conf in range(nb_confusion):
with open(f"confusion_iota2_{nb_conf}.txt", "w") as conf_file:
conf_file.write(str(nb_conf))
class report(i2_step):
"""class to simulate classifications"""
def __init__(self):
super(report, self).__init__()
for conf_file_number, conf_file in enumerate(i2_step.confusion_files):
report_task = self.i2_task(task_parameter={
"f": self.do_report,
"report_file": f"report_{conf_file_number}.txt",
"confusion_file": conf_file
},
task_resources={
"cpu": 2,
"ram": "10Gb"
})
self.add_task_to_i2_processing_graph(
report_task,
task_group="final_report",
task_sub_group=conf_file_number)
def do_report(self, report_file, confusion_file) -> None:
"""
"""
print(
f"generetating report : {report_file} thanks to {confusion_file}")
os.remove(confusion_file)
Warning
It is important to note that to build its tasks, the report class relies on the class attribute i2_step.confusion_files. This attribute must, of course, have a value before calling the class constructor. This attribute can, for example, be updated in the callback function of the appropriate container :
def callback_function(self):
import glob
confusion_files = glob.glob("confusion_iota2_*.txt")
i2_step.confusion_files = confusion_files
def build_steps(self) -> List[step_container]:
"""prepare steps sequence"""
from functools import partial
steps_part_1 = step_container("part_1")
steps_part_1.append(partial(learn_model))
steps_part_1.append(partial(classifications))
steps_part_1.append(partial(confusion))
steps_part_2 = step_container("part_2")
steps_part_2.callback = partial(self.callback_function)
steps_part_2.append(partial(report))
return steps_part_1, steps_part_2
The full scheduling script is available at : i2_dask_scheduling.py
Then an execution trace can be:
>>> python i2_dask_scheduling.py 1 4
I'm learning model_1.txt thanks to my_database.sqlite
I'm learning model_2.txt thanks to my_database.sqlite
classification of Classif_1.tif thanks to model_1.txt
number of random confusion file : 3
generetating report : report_0.txt thanks to confusion_iota2_0.txt
generetating report : report_1.txt thanks to confusion_iota2_1.txt
generetating report : report_2.txt thanks to confusion_iota2_2.txt
We can see that the unpredictability of the use of the confusion class is correctly managed through the use of several dask graphs. Indeed, for 3 produced confusion files, 3 corresponding reports are generated.
This script provides the main components of scheduling in iota2. Most of the functions presented in this script are used as is in iota2. Developers will be able to find these functions in the Iota2.py, Iota2Builder.py and IOTA2Steps.py modules.